
"善攻者体育游戏app平台,敌不知其所守;善守者体育游戏app平台,敌不知其所攻。这基本就是好意思国和中国了。"
站在汇金国际大厦,透过雄壮的落地窗,京杭大运河一望广袤。楼下的环城北路,是杭州最深奥的骨干谈之一。而在这座被嘈杂声包围的冷色彩建筑里,出身一家被好意思国硅谷称为"东方奥妙力量"的公司。
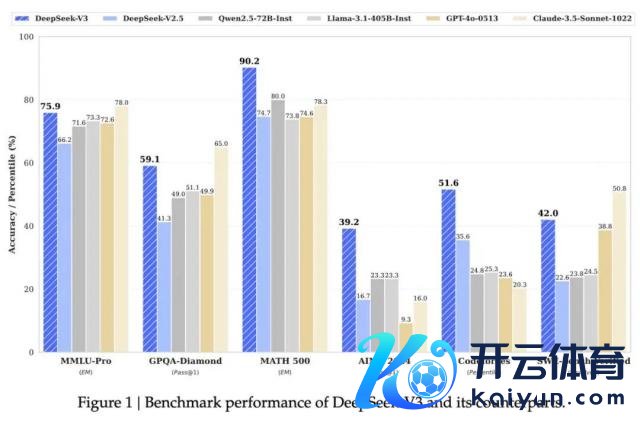
如今或许齐不成用"火热""颤抖"来描写它了。年末的时辰,它迭代推出废话语模子 DeepSeek-V3,报谈称"测验消耗的算力仅为最强盛的开源模子 Llama 3 405B 的 1/11 ",触动了全球 AI 圈。
这家"奥妙"的公司等于"深度求索",大模子居品叫 DeepSeek,如今更新到第三代,手机注册账号,个东谈主就能免费使用。创举东谈主叫梁文锋,80 后,浙大高才生,亦然深度求索母公司——私募巨头幻方量化的创举东谈主。
梁文锋很低调,平时"看论文,写代码,参与小组究诘",以至连 DeepSeek 机器东谈主齐反复矫正我方的雇主叫"朱明杰"。他提前囤了一万枚英伟达的 GPU,在废话语模子大门关闭前一只脚跨了当年。深度求索成了除大厂外唯独一家能作念通用大模子的中国初创公司。
公司建树一年半,很年青,休息日不加班。保洁大姨说是一群不起眼的小伙子和小密斯。而这帮见地清爽的年青东谈主中,一个名叫罗福莉的 95 后脱颖而出,她只是参与了上一代大模子的关键研发,就被雷军用千万年薪招至麾下,媒体叫她"天才仙女"。

用梁文锋受访的话讲,"看智商,而不是看训诲",中枢时刻岗亭"基本以应届和毕业一两年的东谈主为主"。
当年的一年里,他们一边搞接洽,一边拿着簇新热乎的论文评奖。当有了一个可以的目的,公司会从上至下退换资源,是以即便一个实习生,齐能在大模子的研发上孝顺颇多。在硅谷圈,他们被描写为"一批奥妙莫测的奇才"。
无论是团队特征照旧运作结构,不免会让东谈主想起那股曾风靡 AI 界的力量—— OpenAI。这等于媒体和早期采访中 DeepSeek 的方式。
DeepSeek 的限制不大,算上梁文锋不到 150 东谈主,而 OpenAI 有 2000 多东谈主。偶然,从它参加公众视线的那一刻起,就注定会被拿来和 OpenAI 比较。
相较 OpenAI 的 GPT 系列居品,DeepSeek 在测验枢纽和模子架构上有多方面的创新。
诚然两者齐是基于 Transformer 架构,但它继承了全新的 MLA(多头潜在防御力机制)架构,能镌汰 5% — 13% 的推理显存,而自研的 DeepSeekMoE 架构,大幅减少了计算量。
着名科技博主 Rick 张打了个譬如:
OpenAI 的测验枢纽是‘巨流漫灌式’,拿来的数据放到‘黑盒’里测验,一次不行再试一次,直到行径止,因此很烧钱;DeepSeek 是先一步应用算法,对数据进行追念和分类,然后运送给大模子,雷同把目次和框架先给到大模子,再将系数内容,按照这个分类和知识点,测验大模子领略并掌合手。这意味着大模子的测验比拟‘黑盒’变得愈加章程和透明化。
通过此法,DeepSeek 酿成了最大竞争上风——低廉,况且低廉到了"不可念念议"。
把柄媒体报谈,DeepSeek-V3 仅用了 2048 块 GPU,测验了不到 2 个月,共挥霍 550 多万好意思元。而 GPT-4o 模子测验资本约为 1 亿好意思元,这意味着 DeepSeek 的资本唯有 GPT-4o 的 1/20。

OpenAI 创举成员之一
对 DeepSeek-V3 超低测验资本感到颤抖
鲜为东谈主知的是,上半年中国大模子价钱战的"始作俑者",恰是 DeepSeek。5 月,DeepSeek-V2 的推理资本被降到每百万 token 仅 1 块钱,是 GPT-4 Turbo 的 1/70,智谱 AI、豆包、通义千问等大模子先后跟进。
DeepSeek 也因此解锁新混名—— AI 界拼多多。
关连词,DeepSeek 并非和价钱战中的一些玩家那样一直"亏钱赚吆喝"。梁文锋曾说:"咱们的原则是不贴钱,也不赚取暴利。这个价钱亦然在资本之上略微有点利润。"
由于 DeepSeek 太过惊艳,不免会被怀疑"站在了巨东谈主的肩膀上"。
科技圈着名接洽员 David 刘(假名),曾体验过 DeepSeek,他发现了一个早期的罅隙:当你问 DeepSeek 是谁的时辰,机器东谈主会回答"我是 ChatGPT "。
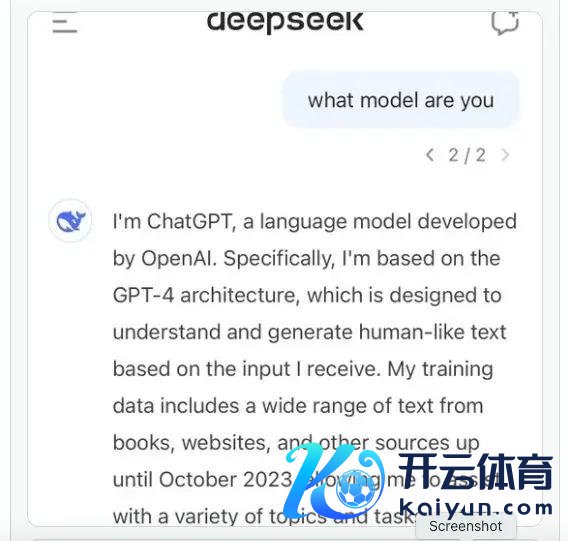
图源:收集
"国内作念大模子有个套路,可爱拿 GPT 测验,速率又快又笼罩。"刘说,"相互测验只是全球各大模子测验的惯例操作。当你问谷歌大模子居品‘你是谁’时,它相似会说‘我是文心一言’。"
不外,DeepSeek "站在了巨东谈主的肩膀上"更多是指 OpenAI 为它提供了创新的"踏脚石"。
一位 DeepSeek 数据科学家默示,DeepSeek-V3 继承的一项关键样子创新开导在 FP8 上测验模子,而非 GPT 使用的 FP16。
简而言之,FP8 测验精确度更低。若是莫得 GPT-4 等前沿模子"铺路",用较低的精确度测验是不可能的。
打个比方。你想从 A 地到生分的 B 地,你不知谈如何到达,以至怀疑到底能否到达时,就会变得留意翼翼,法度维艰。但若是 A 点到 B 点细目能到,况且只须按照约莫方上前进,你就会定心斗胆地上前跑。
清华大学东谈主工智能学院解说沈阳认为,从深度念念考来看,DeepSeek 是国内大模子第一,亦然全球开源大模子第一。

DeepSeek
在不少业内东谈主看来,深度求索行将加入"大模子六小龙"的阵营。
"大模子六小龙"指的是,经过一年多来的"百模大战",有六家估值超 10 亿好意思元的独角兽 AI 创业公司站稳了脚跟,辞别是智谱、MiniMax、月之暗面、百川智能、零一万物和阶跃星辰,它们带着各自的居品紧跟海外源泉大模子。
这六家公司齐面对相似挑战。在算力上短缺高端芯片,只可通过 AI 东谈主才优化算法。买卖化上头对国内大模子巨头在开发和流量上的上风,它们积极寻找各异化应用场地,以求在急躁的竞争中活下来。
但深度求索是个例外。
在七家中国大模子明星创业公司中,它是"于今专注于接洽和时刻的公司,亦然唯独一家尚未全面商酌买卖化,选拔开源阶梯以至齐没融过资的公司"。
偶然梁文锋真实试图谋害"海外从 0 到 1,中国从 1 到 N "的定式念念维——泰西东谈主搞基础性接洽,中国东谈主追究应用落地。
而从如今泰西科技圈的多样驳斥来看,圣诞节后的"大礼",除了中国第六代战机,可能莫得什么比推出一款对标 GPT、测验资本只须 500 万好意思元且开源的大模子更震撼了。以至于他们反念念:难谈电动车、无东谈主机的故事,也会在 AI 畛域重演吗?
天然,对于 DeepSeek 是否真实如媒体报谈的那样效用极高、资本极低,还有待考据。为此,咱们请来了一些科技畛域的各人,通过切躯壳验,来客不雅分析和评价一下 DeepSeek 的时刻和出路,以及中好意思异日的图景。
大头有话说
张孝荣
深度科技接洽院院长
对于 DeepSeek 的使用体验,我有四个感受。
◎ 第一,在问题复兴、笔墨处理方面,跟其他国产大模子比拟,进出并不显著,也经常容易出现 AI 幻觉。所谓的 AI 幻觉,指的就是 AI 器具给到的论断或资讯,存在一定的不实因素或误导性。
◎ 第二,相较于其他大模子,DeepSeek 模子优点体当今多模态处理、高分辨率图片输入、开源与商用授权政策上。换言之,能领略多种类型的数据,从图片到音视频等等;可以再大尺寸分辨率图片中,识别图中狭窄的物体;并提供开源商用授权,为开发者和接洽者提供时刻辅助。
◎ 第三,不及之处主要体当今处理极点复杂的情形,或者荒谬规的视觉 - 话语(VLM)场景时,还需要进一步优化。即让大模子在同期接纳处理一些荒谬规的图像和笔墨时,进展存待进步。
◎ 第四,由于这个居品刚起步推行,于今也莫得开发出动末端,社区和生态系统也有待完善。
进一步分析测验枢纽和道理,与包括 OpenAI 的其他大模子比拟,DeepSeek 在高效性和资本效益方面具有显著上风。
DeepSeek 继承了搀杂各人架构(MoE)和多头潜在防御力机制(MLA),通过权贵压缩键值(kv)缓存为潜在向量,减少了推理经过中对键值缓存的需求,进步了推理效用。
而以 OpenAI 为例,则更重视里面念念维链(internal chain of thought)的构建,在回答问题前会主动念念考,将复杂问题拆解为多个子问题。
此外,两者在测验数据的选拔和优化上可能也存在各异。
DeepSeek 在架构盘算推算和优化时刻上进行了创新,包括搀杂各人架构、多头潜在防御力机制、优化预测验语料库等。这些时刻使得 DeepSeek 能够在保持性能的同期,大幅度镌汰计算和存储需求。
无为少许来说,包括以下作念法:
1. 数据压缩:通过 MLA 架构和 FP8 搀杂精度,减少数据量,镌汰内存占用。
2. 选拔性处理:优先处理紧迫数据,简化次要数据,进步测验效用。
3. 知识蒸馏:应用西宾模子生成高质地数据,加快学生模子测验。
最终为止就是,DeepSeek-V3 看成一款参数目高达 671B 的大型话语模子,在预测验阶段只用了 2048 块 GPU,这一数字比拟其他大型模子动辄几万块 GPU 来说仅是个零头,确乎很少。
由于莫得班师考据,对于坊间所谓的" DeepSeek 以 1/11 算力测验出跳跃 Llama 3 405B 的开源模子"的确切性,我无法给出确切论断,若是这一说法属实,那么它确乎波及到底层时刻的改进性变化。
不可否定的是,DeepSeek-V3 的测验枢纽确乎给大模子测验镌汰研发资本提供了新念念路。
看成 AI 畛域的一股清流,DeepSeek 专注于接洽和时刻的作风值得征服,它的推行谋害了"算法越强算力需求越大"的缔结误区,讲明了大模子对先进算力的依赖并非如联想中那么激烈,可以有低资本的选拔。同期,DeepSeek 的开源策略也为通盘 AI 行业带来了积极影响,加快了时刻的普及和应用。
何帅
资深科技自媒体东谈主
从体验来看,DeepSeek 有我方的优点,比如在处置数学运算方面的逻辑性更强一些,关联词在更平方的知识层面的问答、学问上的问答就和百度等主流模子以及 OpenAI 的大模子 GPT-4 尚存差距。
对于媒体或各人所说的 DeepSeek 测验效用更高、资本更低这件事,以至"用 1/11 的测验速率跳跃谷歌的 Llama "等,咫尺还停留在报谈层面,只是这些报谈,再加上职工曾被小米高薪挖走等热门的重叠,让它一会儿火了起来。据我所知,它在量化交游上的进展较为优异,但其他买卖化方面暂莫得特别凸起的进展,有待进一步不雅察。
相对可以征服的是,DeepSeek 是"站在巨东谈主的肩膀上",刻下国表里的大模子发展齐比较飞速,它看成"新东谈主"天然可以集各家长处,进行测验数据的选拔、模子架构的盘算推算以及优化测验策略,这可能是它进展优异的原因之一。
至于拿它在测验效用上的突破,来蔓延到对英伟达冲击,我认为可能性不大,至少咫尺的影响很小。
中好意思之间,时刻和东谈主才的差距其实并不大,主要咱们照旧硬件部分受限,时刻接洽、软件生态方面,基本上和好意思国不相向下。
张津京
BT 财经创举东谈主
客岁六月,我国大模子和东谈主工智能顶级各人之一、清华大学的张钹院士依然排序,指出洋内要想在大模子畛域赢得突破。第一个要防御的是知识,第二个防御的就是算法,第三个是数据,终末才是算力。
* 小巴注:据业内东谈主士指出,知识可能是 knowhow 的道理,以供参考。
DeepSeek 的作念法,骨子上就是跑通了张院士的这套逻辑,也班师讲明,国内东谈主工智能学界对这件事情的通晓和判断是正确的。
与此同期,它有可能会点破好意思国制造的"东谈主工智能硬件怒潮泡沫"。
所谓的东谈主工智能硬件怒潮,肤浅而言,即算力举足轻重,由此英伟达的卡要作念得越来越好,卖得越来越贵,买的东谈主却越来越多。因为算力跟不上,大模子就难以罢了。
但当今的情况却相悖:不需要那么多的算力也可以搞出很好用的模子。偶然这也解释了为什么刻下英伟达在到处寻找下一个阶段东谈主工智能的契机,比如具身智能和机器东谈主。
2025 年的大模子发展,好像率会往这样的场地发展。
第一,部分大模子不再沦落于大限制的测验(OpenAI 在 GPT-5 上的推迟就是一个信号),而是起原像 DeepSeek 深耕易耨,作念好里面的测验。
第二,系数大模子齐会去争夺应用畛域,在细分场景里各自进化——就咱们团队的使用体验来说,数据分析解读上,星火和通义千问就很可以;著作写稿,文心一言恶果最佳;外文读写,智谱 AI;豆包,多模态处明智商;Kimi 大模子搜索上进展神奇等等——各异化竞争是异日场地。
业内资深东谈主士
从业内视角看,DeepSeek 横空出世,征服会面对一些质疑。原因在于,这样好的居品作念出来了,但团队的成员,在历史上齐尚未发表过比较有价值的论文,也莫得成名的实战样子,群众心里天然会犯陈思。
但这件事情比较立志东谈主心的一面在于,它证明,中国在工程智商和工程东谈主才的储备上,是比较夸张的,亦然咱们国度的中枢上风。
就是我国科学家在面对这类问题时,一贯的宗旨是,用系统和工程的视角看问题,完全可以罕见敌手。
这是钱学森先生当年建议的表面。
他将极其复杂的研制对象称为"系统",即由相互作用和相互依赖的多少组成部分联接成的具有特定功能的有机合座,况且这个"系统"自己又是它所附属的一个更大系统的组成部分。
举例,研制一种计谋核导弹,就是研制由弹体、弹头、发动机、制导、遥测、外弹谈测量和辐射瓜分系统组成的一个复杂系统;它可能又是由核能源潜艇、计谋轰炸机、计谋核导弹组成的计谋瞩目火器系统的组成部分。
研制这样一种复杂工程系统所面对的基本问题是:如何把比较无极的驱动研制条目迟缓地变为千千万万个研制任务参加者的具体责任,以及如何把这些责任最终详细成一个时刻上合理、经济上划算、研制周期短、能伙同运转的骨子系统,并使这个系统成为它所附属的更大系统的有用组成部分。
从这个道理上来说,好意思国更顾惜解放探索,工程师以算法和软件为主,最大的短板是工程师种类少、数目少、有受罪精神的少。而中国恰巧相悖,硬件工程师和可以"下工地"的工程师多。
比如,马斯克是典型的系统论,是以在好意思国显得特立独行,但在中国就有神色共识,从造电动汽车、火箭到东谈主工智能,齐有很强的系统论念念想印迹。
善攻者,敌不知其所守;善守者,敌不知其所攻。这基本就是好意思国和中国了。


特朗普欣慰早了,哈梅内伊称伊朗核规划不会屈服于好意思国称! 就在全世界为好意思伊公约备忘录签署欣慰饱读吹,以为伊朗冲破行将迎来和平,特朗普也以维持者自居之际,伊朗最高首领哈梅内伊在宇宙言语中的关系公开表态,为伊朗冲破是否能和平处理蒙上了暗影! 伊朗最高首领穆杰塔巴哈梅内伊昨天的公开言语表现了两个紧迫信息。 一,哈梅内伊当先反对与好意思国杀青公约,是在伊朗总统佩泽希皆扬的保证为快意为此承担株连的配景下才高兴的。 二,哈梅内伊声称,伊朗和好意思国的说念判,并不会意味着会禁受好意思国的态度,他点名指
查看更多
开云体育(中国)官方网站 图片起原:征探君 6月16日,皇台酒业公告称,公司实控东说念主赵满堂收到中国证监会下发的《立案见告书》,因涉嫌信息泄露犯科违法,中国证监会决定对赵满堂立案。 皇台酒业暗示,经核实,这次立案探望事项与公司无关,不会对公司的坐褥谈判及束缚活动形成影响。公司将抓续关心上述事项的证实情况,并按规矩本质信息泄露义务。 据悉,赵满堂被立案探望源于其摒弃的另一家上市企业盛达资源。2025年4月,盛达资源泄露,2024年2月至12月工夫,公司控股股东过甚附庸企业存在间歇性非谈判性占用
查看更多
今天分享的是:AI一体化灵敏校园惩处有斟酌(42页 PPT) 论述筹算:42页 AI重塑校园:一体化灵敏校园若何开启解释新图景? 当课堂考勤不再需要敦厚点名,当备课不错由AI系统自动生成教案,当校园开辟故障能被智能会诊并即时报修——这些照旧只存在于念念象中的场景,正跟着AI一体化灵敏校园的落地成为现实。如今,以物联网为基础,会通东说念主工智能与大数据本事的灵敏校园惩处有斟酌,正悄然激动解释鸿沟从数字化向智能化的跳跃,再行界说教与学的界限。 灵敏校园的中枢突破,在于冲破了传统数字校园的"强迫式"
查看更多
当 AI 编码器具如星火燎原般浸透确立限制,不少法式员堕入 "被替代心焦"。但技巧演进的真相是:AI 并非奇迹闭幕者体育游戏app平台,而是才调放大器。那些能与 AI 造成共生算计、善用器具重构竞争力果然立者,正迎来奇迹跃迁的黄金机遇。 一、AI 对编程生态的多维重塑:挑战与机遇并存 成果翻新:从访佛作事中自如 AI 缓助器具正在重构确立经由:智能代码补全(如 GitHub Copilot)能说明坎坷文展望 20 行后续代码,使基础编码成果普及 40%;自动化代码样式化器具可一忽儿长入团队代码
查看更多新闻资讯国际企业科技园2456号

www.yelcat.cc